一、LangChain 生态
1) 一张表对齐
| 维度 | 代理框架 | 代理运行时 | 代理工具 |
|---|---|---|---|
| 价值 | 抽象与集成:统一模型、工具、消息与 Agent 循环的写法,降低上手成本。 | 持久执行、流式、人工干预、状态持久化、低级别编排控制。 | 预定义工具、提示与子代理等开箱能力,面向复杂、长程任务。 |
| 场景 | 快速做 Demo / 内部工具;需要标准化团队构建方式;代理逻辑相对直白、编排不极端复杂。 | 长期运行、强状态的工作流与代理;要把确定性步骤与 Agent 步骤混编;要上生产的图执行与检查点。 | 更自主的代理;面对复杂、非确定性、需规划分解与多工件(搜索摘要、脚本、中间状态)的任务。 |
| 业界选项 | LangChain、Vercel AI SDK、CrewAI、OpenAI Agents SDK、Google ADK、LlamaIndex 等。 | LangGraph、Temporal、Inngest 等持久/工作流引擎。 | Deep Agents SDK、Claude Agent SDK、Manus、各类「编码向」CLI Agent 等。 |
2) 分层:从协议到封装
| 层级 | 组件 | 核心职能 | 主要依赖 |
|---|---|---|---|
| 底层协议(地基) | langchain-core | Runnable、BaseMessage、抽象模型类等契约;LCEL 管道建立在其上。 | 无(生态内最底抽象) |
| 外部集成(砖块) | langchain-community | 向量库、Loader、Tool 等第三方集成实现。 | langchain-core |
| 逻辑编排(骨架) | LangGraph | 有状态图执行:循环、分支、Checkpointing、人机协同等运行时能力。 | langchain-core |
| 应用框架(大楼) | LangChain | Chain、RAG、新版 Agent(如 create_react_agent)等高层 API;LangChain 1.0 构建在 LangGraph 之上,但日常用 LangChain 不必先精通 LangGraph。 |
core、community、pydantic 等 |
| 高级封装 | Deep Agents | 基于 LangGraph 的约定式高层封装,减少手写节点与边。 | LangChain、LangGraph |
官方/厂商包不在 社区包langchain-community 之内,而是与 community 并列的独立包。
3) 代理框架(以 LangChain 为例)
- 希望较快搭出代理或半自主应用。
- 需要模型、工具、Agent 循环的团队级标准抽象。
- 要合理默认、上手友好的框架,又不必一上来就做极重编排。
- 应用形态偏简单代理,没有复杂长程状态机需求(或愿意先不碰底层图)。
4) 代理运行时(以 LangGraph 为例)
运行时解决的是在生产里怎么跑,常见能力包括:
- 持久执行:故障后可恢复,长任务从中断点继续。
- 流式:工作流与模型输出流式透出。
- 人工干预:检查、改写代理状态,再交回执行。
- 持久化:线程内与跨线程的状态管理策略。
- 低级别控制:不依赖高层糖衣,直接编排节点与边。
LangGraph 是面向长期运行、有状态代理的低级别编排 + 运行时;它适合反思、重试、多轮工具调用。
5) 代理工具 / 深度代理 SDK(以 Deep Agents 为例)
- 规划:待办列表式跟踪多任务进度。
- 任务委派:子代理分担子任务,主上下文更干净。
- 文件系统:对可插拔存储后端做读写抽象。
- 令牌管理:对话摘要、超大工具结果驱逐等上下文工程。
Deep Agents 构建在 LangGraph 之上,面向需要规划与分解的复杂多步任务(搜索工件、脚本、中间状态并存)。
何时优先用 Deep Agents:
- 代理运行时间长、步骤多。
- 任务复杂、非确定性强,需要内置规划与上下文治理。
- 想直接用预置工具(如文件、bash 类能力、自动上下文工程)。
- 希望沿用预置提示与子代理模式,少从零搭图。
二、LangChain 组件架构
1) 核心组件如何串成应用
2) 核心流程
- 输入处理:把原始数据变成结构化
Document。 - 嵌入与存储:将文本变为可检索的向量并存入向量库。
- 检索:按用户问题召回相关上下文。
- 生成:由 Chat 模型生成回答,并可与工具循环交互。
- 编排:相对「用户问题 → Retrievers → Relevant context → Chat models」的单次流水线,Agents 根据观察决定何时调用 Retrievers、何时调用 Tools(如联网搜索);Chat models 综合 Relevant context 与 Tool results,若信息不足,Agents 可再次检索或换工具,形成决策闭环。Memory 保存消息历史与状态,在用户当前问题进入 Embedding models / Retrievers 前补全会话。
3) 官方组件分类表
| 类别 | 用途 | 关键组件 | 典型场景 |
|---|---|---|---|
| Models | 推理与生成 | Chat models、LLMs、Embedding models | 文本生成、推理、语义理解 |
| Tools | 外部能力 | API、数据库等 | 联网搜索、取数、计算 |
| Agents | 编排与推理 | ReAct、tool-calling agents | 非确定性工作流、决策 |
| Memory | 保留上下文 | Message history、custom state | 多轮对话、有状态交互 |
| Retrievers | 信息访问 | Vector retrievers、web retrievers | RAG、知识库检索 |
| Document processing | 数据摄入 | Loaders、splitters、transformers | PDF、爬虫等 |
| Vector Stores | 语义检索 | Chroma、Pinecone、FAISS 等 | 相似度搜索、向量持久化 |
4) 常见模式(示意)
RAG(检索增强生成)
带工具的 Agent
Agent 与 Memory:如何把环节串成「有状态的」应用
三、LangChain Memory
1) Memory 是什么
Memory是让系统记住先前交互信息的机制。对 AI Agent 而言,记忆能保留对话脉络、从反馈中学习并适应用户偏好;任务越复杂、交互越多,记忆越影响效率与体验。
按召回范围可分为两大类:
- 短期记忆:又称 thread(线程)范围记忆——在同一会话内维护消息与状态;由 LangGraph 纳入 Agent 的 state,通过 checkpointer 持久化,使线程可随时恢复。图每执行一步会更新 state,下一步开始时会读取该 state。
- 长期记忆:跨会话、跨 thread 共享的用户级或应用级数据;可在任意时刻、任意 thread 中召回;按自定义 namespace 划分,不限于单一 thread id。LangGraph 通过 Store。
2) 短期记忆与管理
短期记忆让应用在单个 thread / 会话内记住先前轮次。Thread 将多次交互组织在一起。LangGraph 把短期记忆作为 Agent state 的一部分,用 thread 粒度的 checkpoint 持久化;state 中除对话历史外,还可包含上传文件、检索结果、生成工件等,从而在隔离不同 thread 的同时为当前对话提供完整上下文。
为何要主动管理对话历史?全文历史可能超出上下文窗口导致报错;即使模型支持超长上下文,过长历史也常带来分心、变慢与成本上升。因此需要在工程上裁剪、摘要或遗忘陈旧内容。
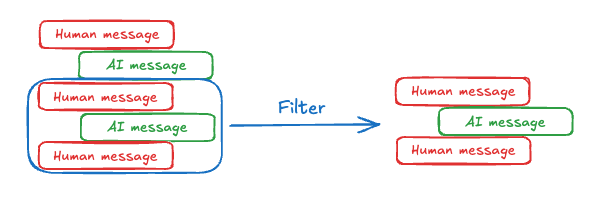
3) 长期记忆
| 类型 | 存什么 | 人类例子 | Agent 例子 |
|---|---|---|---|
| Semantic(语义记忆) | 事实与概念 | 学校里学到的知识 | 关于用户的稳定事实 |
| Episodic(情节记忆) | 经历与事件 | 我做过的事 | 过去 Agent 行为轨迹 |
| Procedural(程序记忆) | 规则与做法 | 本能或熟练技能 | 系统提示、代码与「如何做」 |
4) 语义记忆
注意:心理学意义上的「语义记忆」≠ 工程里的「语义检索(semantic search)」;后者是用向量等手段按含义检索,前者指存事实与知识。
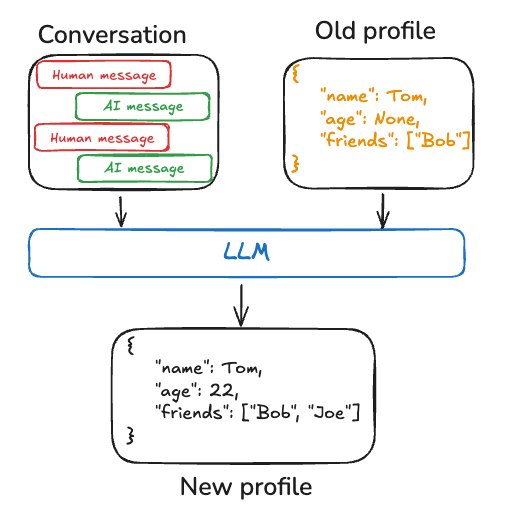
Profile:单一、持续更新的实体画像(如用户/组织),常为受控 schema 的 JSON;每次在旧 profile 上用模型生成新 profile 或 JSON Patch 更新。体量大时易出错,可考虑拆文档或强制结构化解码。
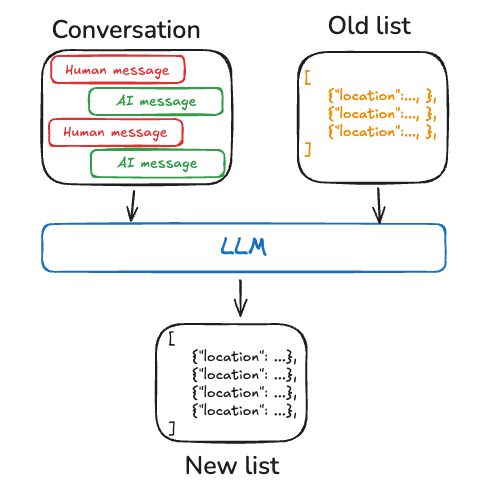
Collection:多条独立记忆文档,随时间追加;单条更窄、更易模型生成,一般更容易保留信息、下游召回更好,但需处理删除/更新与「过增/过改」倾向;检索侧依赖 Store 的语义搜索与过滤。多碎片可能不如单一 profile 那样自带全局语境,组合进 prompt 时需自行设计。
5) 情节记忆与程序记忆
情节记忆:常通过 few-shot 示例 把「过去怎么做」注入提示;可选用 Store 存示例,或用 LangSmith Dataset 自建检索逻辑。
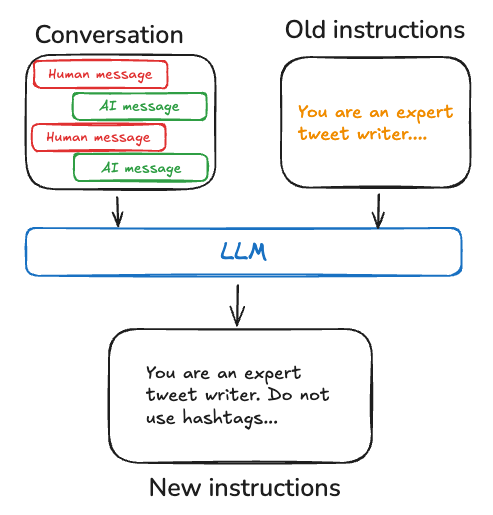
程序记忆:权重、代码与(尤其)系统提示共同决定行为;实践中多见用 Reflection / meta-prompting 迭代系统提示。官方给出基于 Store 更新 instructions 的伪代码思路:call_model 从 Store 读当前指令;update_instructions 结合对话与旧指令生成新指令并 store.put 回去。
# 官方文档伪代码示意(节点拆分)
def call_model(state: State, store: BaseStore):
namespace = ("agent_instructions", )
instructions = store.get(namespace, key="agent_a")[0]
prompt = prompt_template.format(instructions=instructions.value["instructions"])
...
def update_instructions(state: State, store: BaseStore):
namespace = ("instructions",)
instructions = store.search(namespace)[0]
prompt = prompt_template.format(
instructions=instructions.value["instructions"],
conversation=state["messages"])
output = llm.invoke(prompt)
new_instructions = output['new_instructions']
store.put(("agent_instructions",), "agent_a", {"instructions": new_instructions})
...6) 写入记忆:
- 热路径:运行中即时写入——新记忆马上用于后续轮次、可对用户透明;但可能增加工具与推理复杂度、拉高延迟,且与「主要任务」争用注意力。
- 后台:异步提炼记忆——主路径延迟低、职责分离;但确定记忆写入的频率变得至关重要,因为不频繁的更新可能会导致其他线程没有新的上下文。确定何时触发记忆形成也很重要。常见的策略包括在设置的时间段后安排(如果发生新的事件则重新安排),使用 cron 计划,或允许用户或应用程序逻辑手动触发。
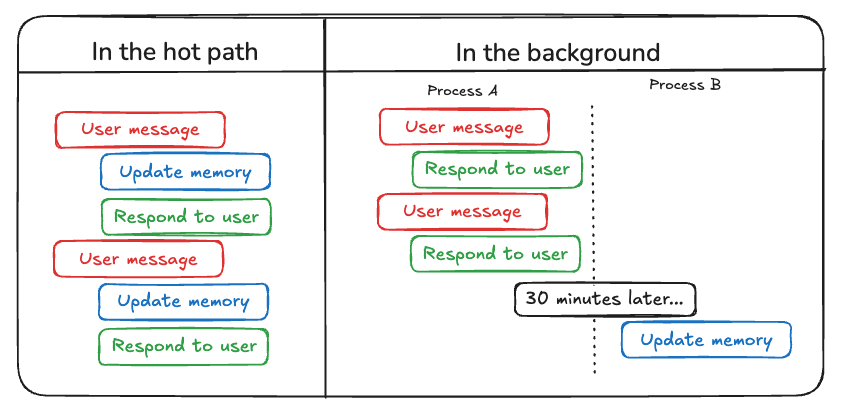
7) 存储结构(Store)
长期记忆在 LangGraph 中以 JSON 文档 存入 store:namespace(类似目录)+ key(类似文件名);namespace 常含 user id、org id 等便于分层与检索。可跨 namespace 用内容过滤等策略搜索。
from langgraph.store.memory import InMemoryStore
def embed(texts: list[str]) -> list[list[float]]:
return [[1.0, 2.0] * len(texts)]
store = InMemoryStore(index={"embed": embed, "dims": 2})
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
store.put(
namespace,
"a-memory",
{
"rules": [
"User likes short, direct language",
"User only speaks English and python",
],
"my-key": "my-value",
},
)
item = store.get(namespace, "a-memory")
items = store.search(
namespace, filter={"my-key": "my-value"}, query="language preferences"
)四、LangChain 上下文
1) 上下文工程
上下文工程(context engineering)指搭建动态系统,在正确时机以正确格式提供正确信息与工具,使应用能完成任务。描述「上下文」常用两个维度:
- 可变性:静态上下文在执行中不变(用户元数据、数据库连接、工具注册等);动态上下文随运行演变(对话历史、中间结果、工具观测等)。
- 生命周期:运行时限定在单次 invoke/单次运行内;跨会话则在多轮对话、多 thread 之间持久存在。
2) 分清:
强调:运行时上下文是代码侧的依赖与数据,不是:
- 写进 LLM 提示里的那段文字(「LLM 上下文」);
- 模型能接收的 最大 token 数(「上下文窗口」)。
运行时上下文更像一种依赖注入:在 invoke/stream 时把用户 ID、客户端、连接等传给工具与节点,再按需写入真正的提示或状态。
3) LangGraph 管理上下文的三种方式
| 类型 | 含义 | 可变 | 生命周期 | 典型访问方式 |
|---|---|---|---|---|
| 静态运行时上下文 | 启动时注入、运行中不变(元数据、工具、DB 连接等) | 静态 | 单次运行 | invoke / stream 的 context 参数;代理里 context_schema;图节点里 Runtime[...];工具里 ToolRuntime[...] |
| 动态运行时上下文(状态) | 单次运行内可变:消息、中间量、工具产出等 | 动态 | 单次运行 | LangGraph state(短期记忆、与 checkpoint 配合可持久到 thread) |
| 动态跨会话上下文(存储) | 跨对话持久:画像、偏好、历史事实等 | 动态 | 跨会话 | LangGraph Store(长期记忆) |
4) 静态运行时上下文
在调用图或代理时通过 context=... 传入;类型可用 @dataclass 等声明为 context_schema。工具与节点通过 runtime.context 读取,避免把连接与用户标识硬编码进工具体。
@dataclass
class ContextSchema:
user_name: str
graph.invoke(
{"messages": [{"role": "user", "content": "hi!"}]},
context={"user_name": "John Smith"},
)代理侧可为中间件动态拼系统提示(request.runtime.context);图节点签名为 def node(state, runtime: Runtime[ContextSchema]);工具侧常用 ToolRuntime[ContextSchema] 注入依赖。
5) 动态运行时上下文(状态)
由 LangGraph 的 state 承载,在一次运行内读写;对应「短期记忆」与多步编排中的中间结果。需要跨多次调用持久化同一 thread 时,结合 Memory 一节中的 checkpointer。
6) 动态跨会话上下文(存储)
由 Store 管理跨 thread、跨会话的数据,对应长期记忆;与上一节「长期记忆 / namespace」一致,可与静态、运行时状态配合:静态上下文决定「谁在读」,存储里放「跨会话记住了什么」。